 El proceso de inferencia consiste en medir un parámetro realizando una selección preferiblemente aleatoria, una muestra mediante muestreo y una vez que calculo el estimador de ese parámetro hago la inferencia, es decir, puedo aproximarme al conocimiento de ese parámetro. Las técnicas de muestreo es un método tal que al escoger un grupo pequeño de una población podamos tener un grado de probabilidad de que ese pequeño grupo posea las características de la población que estamos estudiando. Además de la técnica debemos de tener en cuenta el tamaño de la muestra para estimar de una población. Esta va a depender de la varianza y del tamaño de la población, del error aleatorio y de la mínima diferencia entre los grupos de comparación que se considera importante en los valores de la variable a estudiar. Su fórmula es:
El proceso de inferencia consiste en medir un parámetro realizando una selección preferiblemente aleatoria, una muestra mediante muestreo y una vez que calculo el estimador de ese parámetro hago la inferencia, es decir, puedo aproximarme al conocimiento de ese parámetro. Las técnicas de muestreo es un método tal que al escoger un grupo pequeño de una población podamos tener un grado de probabilidad de que ese pequeño grupo posea las características de la población que estamos estudiando. Además de la técnica debemos de tener en cuenta el tamaño de la muestra para estimar de una población. Esta va a depender de la varianza y del tamaño de la población, del error aleatorio y de la mínima diferencia entre los grupos de comparación que se considera importante en los valores de la variable a estudiar. Su fórmula es:
n = z2 x S2 / e2
- Z es el valor que depende del nivel de confianza 1-α con que se quiere dar a los intervalos calculados a partir de estimadores de esa muestra.
- S2 es la varianza poblacional
- e es el error máximo aceptado
- Si tras esta operación se cumple el resultado N> n (n-1) el cálculo del tamño termina pero si no se cumple, obtendremos el tamaño de la muestra con esta fórmula n'= n/1 + (n/N)
Para calcular el tamaño de una muestra cuando queremos estimar una proporción:
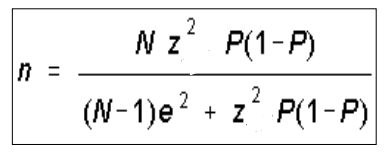
- p es la proporción de una categoría de la variable
- 1-p es la proporción de la otra categoría
- z es el valor que depende del nivel de confianza 1-a
- N es el tamaño de la población
- e es el error máximo aceptado por los investigadores en las diferencias entre los grupos de comparación de la variable a estudiar.
No probabilístico: No utilizan el azar por lo que la muestra no es representativa de una población y hay sesgo de selección. El investigador selecciona la muestra siguiendo algunos criterios identificados para los fines del estudio que realiza. Encontramos:
- Por conveniencia o internacional: en el que el investigador decide, según sus objetivos, los elementos que integrarán la muestra, considerando las unidades “típicas” de la población que desea conocer.
- Por Cuotas: En el que el investigador selecciona la muestra considerando algunos fenómenos o variables a estudiar, como: Sexo, raza, religión, etc.
- Accidental: Consiste en utilizar para el estudio las personas disponibles en un momento dado, según lo que interesa estudiar. De las tres es la más deficiente.
- Estratificado: Se caracteriza por la subdivisión de la población en subgrupos o estratos, debido a que las variables principales que deben someterse a estudio presentan cierta variabilidad o distribución conocida que puede afectar a los resultados.
- Por conglomerados: Se usa cuando no se dispone de una lista detallada y enumerada de cada una de las unidades que conforman el universo y resulta muy complejo elaborarla. En la selección de la muestra en lugar de escogerse cada unidad se toman los subgrupos o conjuntos de unidades “conglomerados”. En este tipo de muestreo el investigador no conoce la distribución de la variable. Las inferencias que se hacen en una muestra conglomerada no son tan confiables como las que se obtienen en un estudio hecho por muestreo aleatorio.
- Sistémico: Similar al aleatorio simple, en donde cada unidad del universo tiene la misma probabilidad de ser seleccionada. Ejemplo:
n=100
4. Aleatorio simple:
Se caracteriza porque cada unidad tiene la
probabilidad equitativa de ser incluida en la muestra:
 De sorteo o rifa: Desventaja de este método es que
no puede usarse cuando el universo es grande.
De sorteo o rifa: Desventaja de este método es que
no puede usarse cuando el universo es grande.
Tabla de números aleatorios: más económico y
requiere menor tiempo.
PROBLEMAS PRÁCTICOS
- Predetermina el tamaño de una muestra necesaria para estudiar la meda del nivel de glucosa plasmática de una población. Aceptamos un riesgo de erros del 1% y pretendemos una precisión de 5mg/ dl. En un estudio anterior la desviación típica resultó ser de 15mg. Calcula el tamaño de la muestra.
e = 5mg/dl
S= 15 mg/dl
riesgo de error 1% →99% de cconfianza deseada → z= 2`58.
n = z2 x S2 / e2
n = 2’582 x 152 / 52 = 59`9 ⤑ n= 60 (el tamaño mínimo muestral para garantizar esprexiones de confianza, siempre redondeamos para arriba)
- Predetermina el tamaño de prevalencia de hipertensión en 5000 habitantes. Un estudio piloto mostró prevalencia del 15%, el nivel de confianza es del 95% y la precisión ±5 %. ¿Cuál es el tamaño de la muestra?
95% → z= 1'96
e= 0'05 (error máx aceptado)
p= 0,15
1-p= 0'85
Utilizamos la fórmula cuando queremos estimar el tamaño en una población:

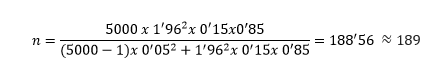
Los sujetos quedeberían meter en la muestra son 189.
Esto ha sido todo por hoy, espero que se haya entendido.
Hasta la próxima!!
Almu❤




No hay comentarios:
Publicar un comentario